Pages blocked from indexing
What is indexing?
Indexing is the process of analyzing site pages (this is normally carried out by search engines) and then after crawling, adding them to search engine indexes. This index (database) is then used to form search results, and also the ranking of pages within the search results (after algorithms further analyze the pages based on query intent satisfaction and successful SEO). Indexing is carried out by a crawler/search engine robot.
Why do we need the ability to exclude information from search engine indexes?
As a rule of thumb, information that should not be displayed in search results can be blocked from search engine indexes by using the “noindex” tag or by blocking crawling of certain sections/pages of the site within the robots.txt file.
Pages normally blocked from search engines are of a technical, proprietary and confidential nature, and are deemed unsuitable for placement in search results.
Examples of this within a commercial site may be links pointing to; users’ accounts, shopping carts, product comparisons, duplicate pages, search results within the site and so on!
These pages are valuable to customers and essential to the functionality of the site, but are not useful to search engine indexes.
Ways to block pages from being indexed by the search engines
There are many ways to prevent the indexing of pages:
-
Using a robots.txt file.
Robots.txt is a text file that tells search engines what pages it can index and which pages it cannot index.
To block a page from being indexed in robots.txt, you must use the Disallow directive.
Example of a robots.txt file that is allowing indexing of catalog pages while disallowing indexing of the cart:
# The content of the robots.txt file, # which must be in the root directory of the site # enable indexing of pages and files starting with '/catalog' Allow: /catalog # block indexing of pages and files starting with '/cart' Disallow: /cart
-
Using the <meta> robots tag with the noindex attribute.
To block a page using this attribute, you need to add the following lines to the
<head>section of the page:To block the entire page from indexing you should place the following line in the
<head>block of the page itself:<meta name="robots" content="noindex">
-
Nofollowing links so they do not index the page that they are linking to.
There are two ways to do this:
-
Blocking the crawler following a link on a link by link basis:
<a href="/page" rel="nofollow"> link text </a>
Bear in mind that this method will only work if every single link to the page has the “nofollow” attribute in it. If one link is missing this attribute then the search engine crawler will follow it and the page will still be indexed.
-
Blocking the crawler following any link with on the page by giving the page itself the nofollow attribute:
By adding the below line to the
<head>block on the page, the crawler will be blocked from following the page and therefore any links contained within the page will not be indexed.<meta name="robots" content="nofollow" />
-
-
You can also block the page from being crawled by any specific search engine in the header of the HTML page, for example:
You can place this line in the
<head>block on the page itself; this will block the page from being indexed by Google (as you have blocked their crawler completely):<meta name="googlebot" content="noindex">
You can also opt to “noindex” a specific page whilst also allowing Google to follow the links on said page, and then index the pages being linked to from the “noindex” page:
<meta name="googlebot" content="noindex, follow">
-
Canonical page.
The rel=canonical attribute is used to indicate to the search engine that the page is a canonical page (the most authoritative one). This indicates to the crawler that this is the preferred page to index and is the most authoritative example of this content on their site.
Specifying canonical pages is necessary to avoid pages with identical content being indexed which can then harm the page’s ranking in the SERP.
You would use this attribute when you have multiple pages with identical content but have different URLs for different devices:
https://example.com/news/https://m.example.com/news/https://amp.example.com/news/
Or when there are several ‘sort’ options available for the page that will alter the page URL but show the same content:
https://example.com/catalog/https://example.com/catalog?sort=datehttps://example.com/catalog?sort=cost
Or if the link specifies the different sizes of a given product within the URL:
https://example.com/catalog/shirthttps://example.com/catalog/shirt?size=XLhttps://example.com/catalog/shirt38
The rel=canonical attribute is applied as follows:
<link rel=canonical href="https://example.com/catalog/shirt" />
Note: you should place this attribute in the
<head>block of the pageIt is also possible to enter the wanted canonical page in the header of the HTTP request.
However, be careful as without the use of special plugins for your browser, you won’t be able to ascertain whether this attribute has been correctly set as most browsers do not show HTTP headers to its users.
HTTP / 1.1 200 OK Link: <https://example.com/catalog/shirt>; rel=canonical
You can read more about canonical pages in the Google documentation.
-
Using the "X-Robots-Tag" HTTP request header for a specific URL:
HTTP / 1.1 200 OK X-Robots-Tag: google: noindex
Be careful as without the use of special plugins for your browser, you won’t be able to ascertain whether this attribute has been correctly set as most browsers do not show HTTP headers to its users.
How do I find pages that have been blocked from indexing on my site?
You can view this information in the "SEO audit" - "Pages blocked from indexing" section of your Labrika dashboard.
On the report page you can filter the results in order to see any landing pages that have been blocked from indexing. To do this you need to click on the “critical error” button.
Typically, when a search engine crawler visits your site, it will crawl all the pages it can find via internal links and then index them accordingly.
The aim of this report is to show any pages that have been blocked from being indexed. These tend to be pages that have no keywords in the top 50 search results, and may have been purposely blocked from indexing by search engines by you.
Labrika’s “Pages blocked from indexing” report
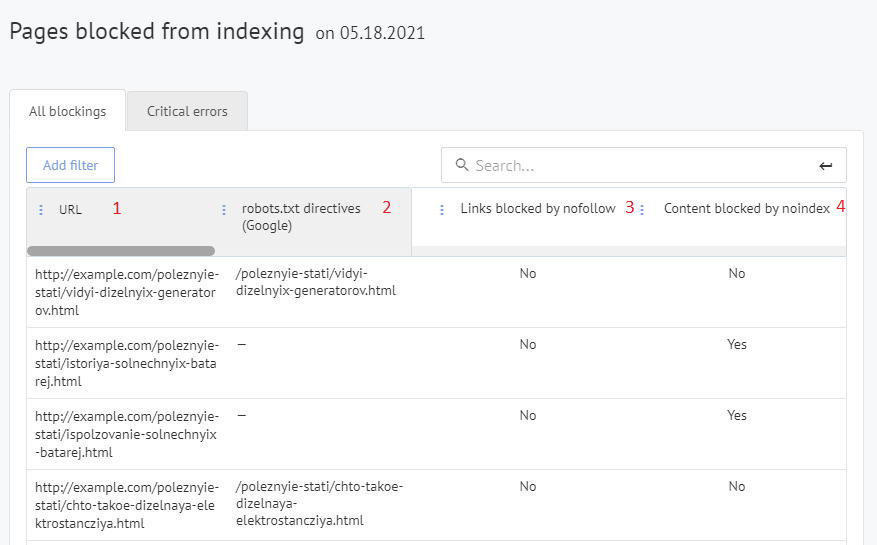
- The URL of any pages that are blocked from indexing currently.
- The directive in robots.txt that is blocking indexing for this page (if the page is blocked from indexing in Google by this method).
- Whether this page has been blocked via the nofollow attribute.
How do I stop a page from being noindexed that is housed within this report?
In many modern content management systems (CMS), you can change the robots.txt file, rel= canonical, "robots" meta tag, “noindex”, and “nofollow” attributes. Therefore, to make a page indexable again that is contained within this report, you would only need to remove the attribute/tag causing this page to not be indexed. There are many simple plugins that allow you to do this. If you are unable to change it yourself it would be a relatively simple task to outsource to a developer.