In sitemap but not available for indexing
A Sitemap.xml file is essentially a map of your website designed specifically for easy navigation and indexing of your site by search engines. It is located within your public_html folder (or site root) and includes important instructions for search engine crawlers that specify what pages should be visited, in what order, and how often to visit them.
This drastically accelerates the indexing process of important pages and allows the search crawlers to allocate their crawl time to pages of high importance to both you and your users.
Creating a sitemap.xml is not always needed but always recommended, especially for large sites with thousands of pages. With bigger sites, comes the need to really make sure search engine crawlers spend their time on those high value pages with deep content and commercial intent, not side pages that offer thin value.
As a rule of thumb, when software and CMS’s automatically generate a sitemap.xml file, they include all available pages for indexing. A typical website owner is not likely to be aware of this, and while they may have set noindex for certain pages, their automatically generated sitemaps are likely including these pages and wasting valuable crawl budgets!
It is highly recommended to use plugins, custom software, or sitemap generators to configure specific URLS to show in your sitemap, certain URL’s to be avoided, what order to crawl URL’s and how often to crawl them.
Sitemap errors found by Labrika
Attention! The sitemap error report will only be accessible if sufficient permissions to scan the whole website are configured correctly. Otherwise, Labrika will only be able to view pages specifically listed in the sitemap.xml rather than being able to view all pages on the website, and then cross-compare them with pages listed in the sitemap.
Labrika sitemap analysis helps find the following types of errors:
-
Pages that exist in the sitemap but are not accessible for indexing.
-
Pages that exist in the sitemap but have a noindex tag.
-
Pages that don’t exist in the sitemap but are indexable.
Please note: different search engines process sitemap rules in different ways. Google, most frequently, will only index pages than can be reached through automatic crawling without a sitemap. That is, pages that can be reached via internal links within the allotted crawl time and crawl depth for your site that day. They will not look at your sitemap.xml file to ascertain which links to crawl, but instead use the sitemap as a guide for how often to crawl pages listed in the sitemap.
Page exists in the sitemap, but is not accessible for indexing
This report highlights mostly orphan pages, which are essentially pages that exist on your site but have no inbound links pointing at them and are ‘ownerless’.
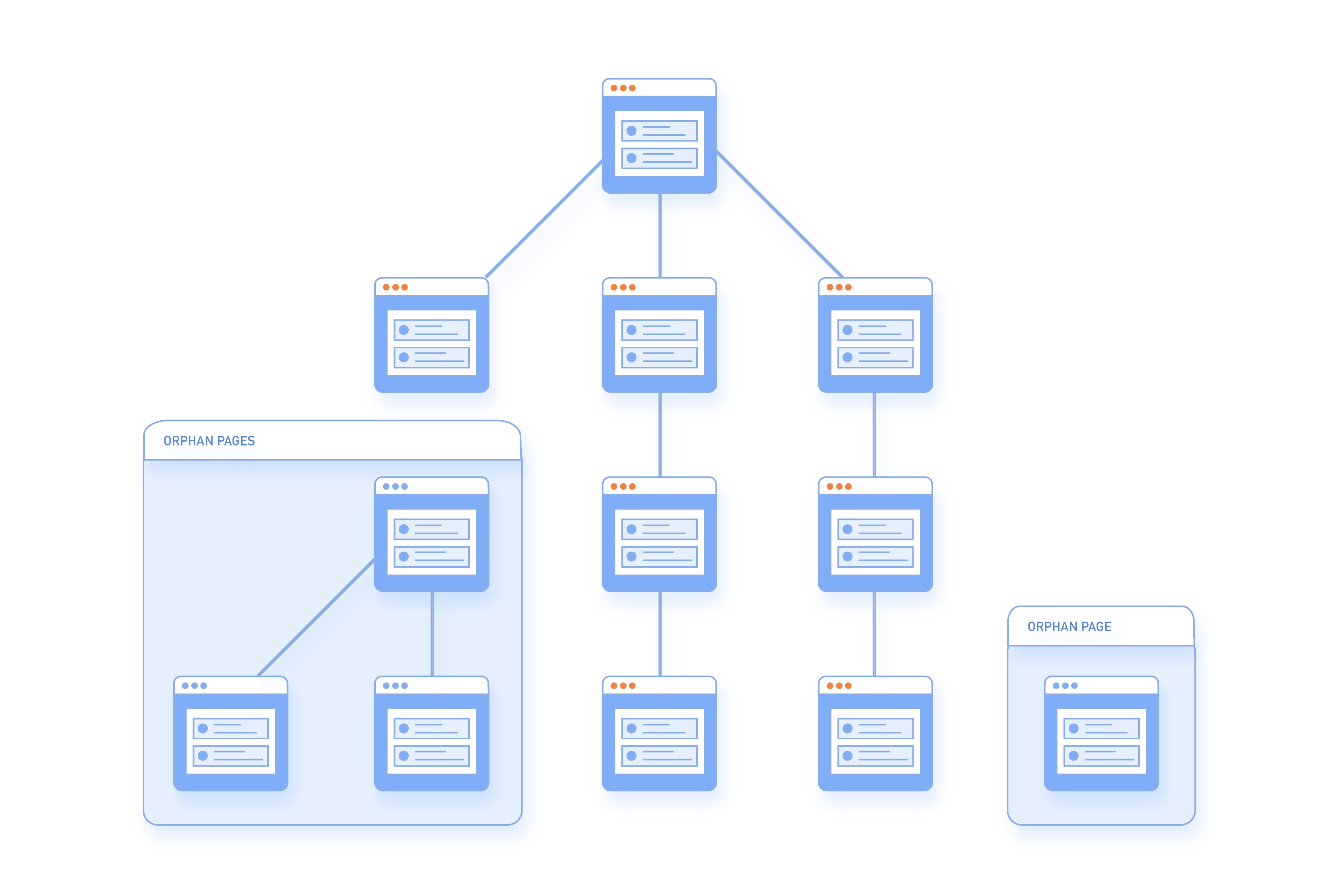
In the event that such pages do somehow get indexed by search engines, they are likely to have zero PageRank and will not rank well. It is well documented online, that Google and other big search engines use PageRank scores (and its various forms) to ascertain the SEO power and value of pages. It was only a few years ago that Google enabled you to utilise a toolbar that showed your pages PageRank, but unfortunately, that was removed from the public sphere. Naturally though, you want good PageRank for your different pages, so if one of your landing pages ends up showing in this error category (i.e. your page is not just an orphan page) then you will want to get to the source of the problem immediately.
Common reasons for your page to exist in the sitemap, but not be accessible for indexing:
-
A link from a noindex tagged page/s leads to this page, or the pages leading to this page are not responsive. As a result, the search engine crawler cannot move forwards or backwards, and therefore ends the session.
-
Links to the needed pages are blocked. For example, through the rel="nofollow" attribute. That is, the crawler sees the link to the page, but cannot navigate to it because it is forbidden.
-
There are no links to this page and it is truly ‘orphaned’.
-
The page was deleted in the website editor/CMS but the HTML file still remains live on the site.
-
The page exists in the sitemap but is not crawlable, so cannot be indexed.
This kind of error is best rectified by doing the following;
Check what pages have noindex and nofollow tags and rectify and/or make sure the page is added correctly to the primary menu to enable correct crawling. Also, more often than not, we see this kind of error with commercial and informational sites that block pagination.
How to fix the issue?
When a page is available in the sitemap but has no internal links from any other page on the site it is known as an orphan page.
Orphan pages are bad for SEO as they carry no link weight and therefore are considered unimportant by the search engines. They were also used previously in black hat SEO.
Once identified in our dashboard you can:
- Re-integrate the page into your site linking scheme if the page is useful, ranks for keywords, or has backlinks from external sites.
- Merge the page with another if it has a near duplicate page already linked to on the site.
- Remove the page entirely if it has no use. Or return a 404, or 410 (expired content) code.
- For product pages where the item may have expired you can link to new products in the same category, making the page a new lead source. (This is what eBay does with expired auction listings). Helping to generate more traffic.
Page exists in the sitemap but has a noindex tag
These are pages that have been forbidden from indexing using a noindex tag but still exist somewhere in the sitemap.
People noindex pages for a variety of reasons but having noindex pages listed in the sitemap can lead to confidential data being leaked but most likely, it results in crawlers wasting their time and crawl budget.
To fix this issue you simply need to remove the noindex page/pages from the sitemap to avoid any search engines inadvertently indexing a page they shouldn’t (although they do normally follow the noindex tag).
How to fix the issue?
This typically occurs when a page has been blocked from indexing through a rel="nofollow" attribute.
Including these pages in the sitemap is not useful as it uses crawl budget and could potentially lead to the leak of confidential information. To fix this you can simply remove the page from your sitemap.
Download Labrika’s error free sitemap.xml file
For each of the different sitemap error reports listed above, Labrika offers you the ability to download an error free, and corrected version of your sitemap.xml file. This should save you time correcting your own sitemap.xml file manually, and most importantly, make better use of your search engine crawl budgets.
