Pages with rel=canonical tag
rel="canonical" is a tag applied to pages that essentially says; “I’m the master copy of this page” to the search engine crawlers when they crawl your site.
A canonicalized page is a page that is recommended for indexation in search engines by you, and carries the weight of the being ‘the’ authoritative page for that page’s specific text, on your site. For example, when a search engine crawler is crawling your site and comes across the rel="canonical" tag on a page, it tells the crawler to trust and index this version of the page on your site. This tag solely exists for the purpose of instructing search engine crawlers, and will not affect user experience like a 301 redirect would.
When is this tag applied?
In a perfect world, the use of rel="canonical" should be redundant as every page on your site would ideally have completely different content. Unfortunately, that is not possible, and there are many occasions where this tag is essential to make sure that the right content gets indexed not a lesser, duplicate version.
One such example is with commercial sites with stores and products. With a pair of shoes for sale you are likely to offer them in different colors, right? Well, each of those different colors of the same shoe are likely to have their own URL when you click on them, but of course, will have the same product descriptions. To the search engine crawler, they are seeing a 99% duplicate page for each of these color variants of same shoe, and thus, are likely to only index one but at random if the rel="canonical" tag does not exist (search engines do not normally index duplicate versions of the same page and instead, only pick one). This can be a big problem for search rankings if you cannot control what pages are getting indexed and what pages aren’t when you have, essentially, multiple versions of the same page.
In this scenario, you could have spent thousands of dollars on getting backlinks and also directing internal links to the black version of your shoe, but without a canonical tag it is impossible to force the search engine to index this page specifically, when a duplicate blue shoe page exists, also without a canonical tag.
To rectify this situation you would simply use the rel="canonical" tag on the black shoe page and state the black shoe page as the canonical link, and on all other color variants of this shoe, you would also use the canonical tag, but, instead link to the “master copy” of this page that would be the black shoe page.
If you have multiple ways to access your site (I.e. http, https, www, non www) that do not use user redirection to send them to your preferred domain name structure, then we would recommend setting the preferred domain name structure as the canonical (if you don’t want to use 301 redirects).
Why is it necessary to know what website pages contain the rel="canonical" tag?
Unfortunately, canonical pages can be indicated incorrectly, which can lead to a substantial loss of SEO rankings and/or no indexation for the correct pages. For example, we have seen people accidentally implement a site-wide canonical tag that instead of stating the “master copy” of each page IS each page, they stated just one page (i.e. your homepage) as the canonical for all pages. We have seen this before and it leads to huge indexing errors, which is why we’ve created this canonical checker for you.
Why is this tag so important for search engines?
The rel="canonical" tag affords search engines the ability to quickly identify the “master copy” of a page that has other pages with duplicate/similar content. This helps the search engine crawler know exactly what page should be indexed and what pages shouldn’t.
Google officially recommends using the rel="canonical" tag to prevent duplicate URL’s. You can read about these guidelines here: Duplicate URL consolidation.
How to decipher and use our rel="canonical" report:
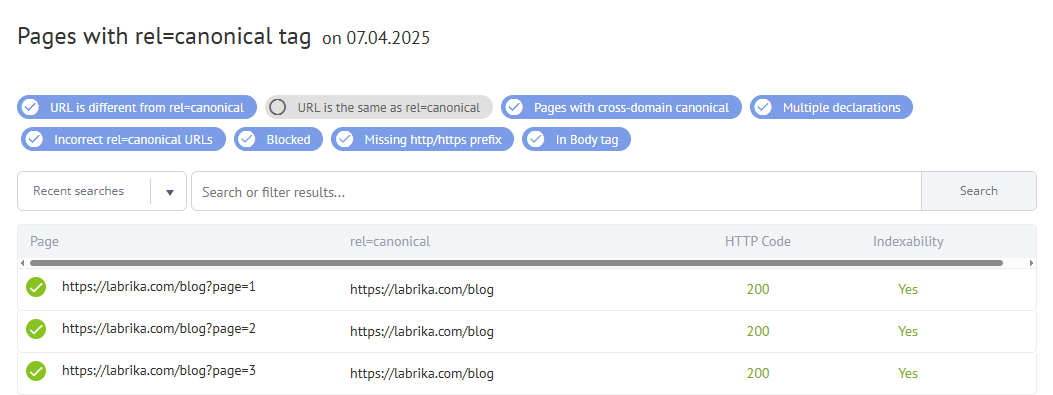
- Column 1. URL of the page where the
rel="canonical"tag was found. - Column 2. The URL indicated in the
rel="canonical"tag as the canonical one (the ‘master copy’). - Column 3. The server response code of the page indicated in
rel="canonical"tag – A 200 response code confirms successful processing of the canonical URL (i.e. the page is accessible for indexing that you have set). - Column 4. “Check” button. Pushing this button allows you to view the content of the
rel="canonical"tag in the page code.
How to manually implement the rel="canonical" tag on a page:
All you have to do is insert the following code between the <head> and </head> section of your html for your desired page: and section of your html for your desired page:
<link rel="canonical" href=" ENTER YOUR CHOSEN CANONICAL URL" />
The chosen canonical URL section of the code is where you enter the full page URL for the page you want to be seen as the ‘master copy’.
For example, if I had two pages, one for black shoes and one for blue shoes, to make the black shoes the canonical page (the ‘master copy’) I would complete the following:
On the black shoe page I would set the black shoe page as the canonical:
Example of the attribute use:
<link rel="canonical" href="https://yoursite.com/black-shoes/"/>
And, on the blue shoe page I would set the black shoe page as the canonical:
Example of the attribute use:
<link rel="canonical" href="https://yoursite.com/black-shoes/"/>
When the search engine crawler visits both the black and blue shoe pages, they will now know based on the two canonical tags (one on the black shoe page, and one on the blue shoe page) that they should index the black shoe page not the blue.