Duplicate content
What is duplicate content?
Duplicate content refers to when multiple pages have identical content available at different URLs on your site.
This is a big SEO mistake.
How does duplicate content affect rankings?
Duplicate pages harm your site's ranking for many reasons:
- Search engines are sensitive to the originality of content housed within web resources. If there are multiple pages with duplicate content, then it is likely that said pages will be penalised by Google and will negatively affect your site's overall rankings in the SERPs.
- The presence of a large number of duplicate pages dramatically complicates the process of site indexing since the search engines have to spend their crawling budget crawling the duplicate pages, rather than your high ranking pages.
- It makes successfully ranking landing pages more difficult as the search engine cannot objectively select a relevant page to rank as there are multiple instances of the same page.
- The "PageRank" and "weight" of the pages are diluted, as internal links are distributed between the duplicate pages.
- Unscrupulous competitors can also find duplicate pages on your site and add external links to them. This will add them to the search engine index and as a result, search engines will lower your website in the search results as you will likely be hit with a duplicate content penalty.
- Google writes in detail on the negative impact of duplicate pages and how to best deal with them in their article titled "Consolidating Duplicate URLs."
The most common causes of duplicate pages are:
-
No 301 redirection being sited for pages with www and without www. In this case, each page of the site is a duplicate since it is available at two addresses.
For example:
http://example.com/pagehttp://example.com/page
-
Site pages are available at the address with and without a slash. If there is no 301 redirection set, then the site software perceives the following pages as different although the content is identical:
For example:
- this URL looks like a folder on the site - it ends with '/.'
http://example.com/page/ - and this URL is like a page - page names may not end with ".php", ".html", etc.
http://example.com/page
- this URL looks like a folder on the site - it ends with '/.'
-
Also, pages can have .php appended to the end of the URL. This causes duplicate pages:
For example:
http://example.com/page1http://example.com/page1.php
-
Pages of product groups with different types of filtering options appended to the URL.
For example:
http://example.com/cataloghttp://example.com/catalog?sort=datehttp://example.com/catalog?sort=name
-
The same product can be present in different sizes and/or configurations of products. The content will be the same on these pages although there will be multiple URLs.
For example:
http://example.com/catalog/shirt155http://example.com/catalog/shirt155?color=Orange
-
Pagination of the e-commerce category pages. The URL with the number of the first page appended to it is processed in exactly the same way as if the system did not pass the parameter with the number at all. Thus, it turns out that the same page has different URLs.
For example:
http://example.com/cataloghttp://example.com/catalog?page=1
-
You may have configured the CMS to ignore and still serve pages with additional parameters added. This is not recommended. If the site does not show a 404 error when you add non-existent parameters to a page then said pages can be indexed and are duplicate.
For example:
- Normal URL
http://example.com/blog - Random appended parameter added to the URL
http://example.com/blog?blablabla=7777
- Normal URL
How to find duplicate pages on your website?
You can find duplicate pages on your site in the "SEO audit" -> Duplicates pages on your site" section of your Labrika dashboard.
Labrika's "Duplicate pages on your site" report:
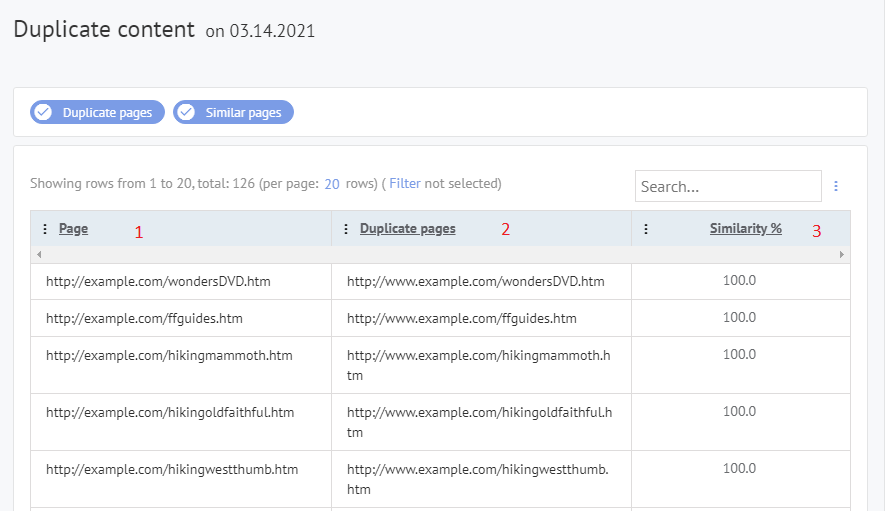
- The URL of the page that has a duplicate.
- List of duplicates of this page.
- Page similarity percentage.
How to eliminate duplicate pages from your website?
Ways to get rid of duplicates:
-
You can eliminate some duplicate page errors by simply removing needless parameters from being allowed in the site editor. In the example below, you can clearly see a link that needs to be cleared up and the second option used instead:
http://example.com/catalog/shirt155?size=XLPreferred option:
http://example.com/catalog/shirt155 -
If there are only a small number of duplicate pages found in our report, then you can simple disallow certain duplicate URLs from being indexed in the first place. For example, you would likely block the crawlers from accessing the catalog folder that is part of the URL to the first page below, so that only the second URL would be indexed by Google:
http://example.com/category/producthttp://example.com/product
You would add the following line of code to block the first page from indexing in your robots.txt file:
# block indexing of duplicate pages located in the '/category' folder: Disallow: /category
-
If duplicate pages appear to be a systemic problem for your entire site, then the
rel=canonicalattribute is the best solution.rel=canonicalis a tag applied to pages that essentially says; "I'm the master copy of this page" to the search engine crawlers when they crawl your site.A canonicalized page is a page that is recommended for indexation in search engines by you and carries the weight of being 'the' authoritative page for that page's specific text, on your site.
You should set the most authoritative page in the list of duplicate pages as the canonical page, and that would instruct search engines to ignore all duplicates of the canonical.
The attribute is written as follows:
# the line should be placed in the <head> block on the page itself <link rel="canonical" href="https://site.com/catalog/shirt" />
Similar pages
Within your duplicate pages report you will also see a "similar pages" section.
Similar pages are pages that differ by only a few words when compared to other pages on your site.
For example, if you took the content of one page, changed only the color of the product, or the name of the city, and then saved it under a different URL, it would likely show up in this similar page report.
Such pages are also likely to trigger duplicate content penalties and should also be addressed by following the same practices and methods listed in the "How to eliminate duplicate pages from your website?" section above.
How to fix the issue
Duplicate content within your site is when multiple pages have identical content.
These pages ruin your site's optimization efforts as search engines are sensitive to duplicate content, it also adds to the crawling budget unnecessarily, dilutes the page rank, and puts you in competition with yourself as the search engines don't know which page to pick.
To fix this, you can:
- Remove needless parameters that create additional URLs that lead to the same page.
- If there are not many pages with the issue you can simply disallow duplicate URLs from being indexed or certain category sections from being indexed.
- Use the rel=canonical attribute to specify the 'master page' of all the duplicate pages. When doing this, set the most authoritative page as the canonical.
Read more here on how to implement these steps: https://labrika.com/help/docs/pages_duplicates.