Robots.txt Validator
Robots.txt is a text file that contains instructions (directives) for indexing site pages. Using this file, you can tell search robots which pages or sections on a web resource should be crawled and entered into the index (search engine database) and which should not.
The robots.txt file is located at the root of the site and is available at domain.com/robots.txt.
Why is robots.txt necessary for SEO?
This file gives the search engines essential instructions that directly influence the effectiveness of a website's ranking in the search engine. Using robots.txt can help:
- Prevent the scanning of duplicate content or non-useful pages for users (such as internal search results, technical pages, etc) by the search engines crawlers.
- Maintain the confidentiality of sections of the website (for example, you can block system information in the CMS from being accessed);
- Avoid server overload;
- Effectively spend your crawling budget on crawling valuable pages.
On the other hand, if the robots.txt contains errors, search engines will index the site incorrectly, and the search results will include the wrong information.
You can also accidentally prevent the indexing of useful pages that are necessary for your site's rankings in the search engines.
Below are links to instructions on how to use the robots.txt file from Google.
Content of the "Robots.txt Errors" report on Labrika
This is what you will find in our "robots.txt errors" report:
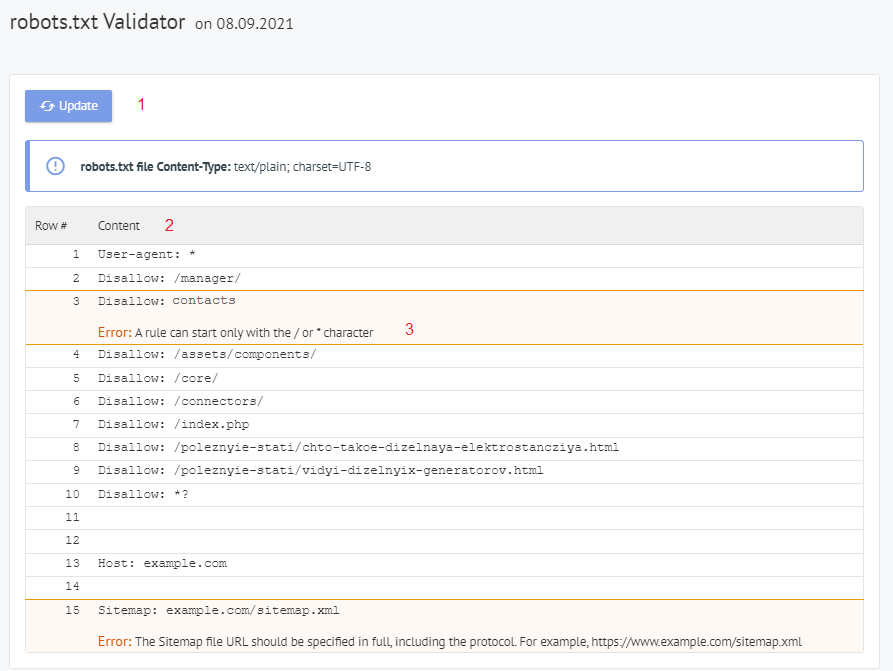
- "Refresh" button - when you click on it, the data on the errors in the robots.txt file will be refreshed.
- The content in the robots.txt file.
- If an error is found, Labrika gives the error description.
Robots.txt errors that Labrika detects
The tool finds the following types of errors:
The directive must be separated from the rule by the ":" symbol
Each valid line in your robots.txt file must contain the field name, colon, and value. Spaces are optional but recommended for readability. The hash symbol "#" is used to add a comment, which is placed before it begins. The search engine robot will ignore all text after the "#" symbol and up to the end of the line.
Standard format:
<field>:<value><#optional-comment>
An example of an error:
User-agent Googlebot
Missing ":" character.
Correct option:
User-agent: Googlebot
Empty directive and empty rule
Using an empty string in the user-agent directive is not allowed.
This is the primary directive that indicates which type of search robot the further indexing rules are written for.
An example of an error:
User-agent:
No user-agent specified.
Correct option:
User-agent: the name of the bot
For example:
User-agent: Googlebot or User-agent: *
Each rule must contain at least one "Allow" or "Disallow" directive. Disallow closes a section or page from indexing. "Allow" as its name indicates allows pages to be indexed. For example, it allows a crawler to crawl a subdirectory or page in a directory that is normally blocked from processing.
These directives are specified in the format:
directive: [path], where [path] (the path to the page or section) is optional.
However, robots ignore the Allow and Disallow directives if you do not specify a way in. In this case, they can scan all content.
An empty directive Disallow: is equivalent to the directive Allow: /, meaning, "do not deny anything."
An example of an error in the Sitemap directive:
Sitemap:
The path to the sitemap is not specified.
Corect option:
Sitemap: https://www.site.com/sitemap.xml
There is no User-agent directive before the rule
The rule must always come after the User-agent directive. Placing a rule in front of the first user agent name means that no scanners will follow it.
An example of an error:
Disallow: /category User-agent: Googlebot
Correct option:
User-agent: Googlebot Disallow: /category
Using the form "User-agent: *"
When we see User-agent: * this means that the rule is set for all search robots.
For example:
User-agent: * Disallow: /
This prohibits all search robots from indexing the entire site.
There should be only one User-agent directive for one robot and only one User-agent: * directive for all robots.
If the same user agent has different lists of rules specified in the robots.txt file several times, it will be difficult for search robots to determine which rules to consider. As a result, the robot will not know which rule to follow.
An example of an error:
User-agent: * Disallow: /category User-agent: * Disallow: /*.pdf.
Correct option:
User-agent: * Disallow: /category Disallow: /*.pdf.
Unknown directive
A directive was found that is not supported by the search engine.
The reasons for this may be the following:
- A non-existent directive was spelled out;
- Syntax errors were made, prohibited symbols and tags were used;
- This directive can be used by other search engine robots.
An example of an error:
Disalow: /catalog
The "Disalow" directive does not exist. There was a mistake in the spelling of the word.
Correct option:
Disallow: /catalog
The number of rules in the robots.txt file exceeds the maximum allowed
Search robots will correctly process the robots.txt file if its size does not exceed 500 KB. The permitted number of rules in the file is 2048. Content over this limit is ignored. To avoid exceeding it, use more general directives instead of excluding each page.
For example, if you need to block scanning PDF files, do not block every single file. Instead, disallow all URLs containing .pdf with the directive:
Disallow: /*.pdf
Rule exceeds the allowed length
The rule must be no more than 1024 characters.
Incorrect rule format
Your robots.txt file must be UTF-8 encoded in plain text. Search engines can ignore non-UTF-8 characters. In this case, the rules from the robots.txt file will not work.
For search robots to correctly process instructions in the robots.txt file, all rules must be written following the Robot Exclusion Standard (REP), which Google supports and most well-known search engines.
Use of national characters
The use of national characters is prohibited in the robots.txt file. According to the standard-approved domain name system, a domain name can only consist of a limited set of ASCII characters (letters of the Latin alphabet, numbers from 0 to 9, and a hyphen). If the domain contains non-ASCII characters (including national alphabets), it must be Punycode converted to a valid character set.
An example of an error:
User-agent: Googlebot Sitemap: https: //bücher.tld/sitemap.xml
Correct option:
User-agent: Googlebot Sitemap: https://xn-bcher-kva.tld/sitemap.xml
An invalid character may have been used
The use of special characters "*" and "$" is allowed. They specify address patterns when declaring directives so the user does not have to write a large list of final URLs to block.
For example:
Disallow: /*.php$
prohibits indexing any PHP files.
- The asterisk "*" denotes any sequence and any number of characters.
- The dollar sign "$" denotes the end of the address and limits the effect of the "*" sign.
For example, if /*.php matches all paths that contain .php., Then /*.php$ only matches paths that end in .php.
The "$" symbol is written in the middle of the value
The "$" sign can be used only once and only at the end of a rule. It indicates that the character in front of it should be the last one.
An example of an error:
Allow: /file$html
Correct option:
Allow: /file.html$
The rule does not start with a "/" or "*"
A rule can only start with the characters "/" and "*".
The path value is specified relative to the site's root directory where the robots.txt file is located and must begin with a slash "/" indicating the root directory.
An example of an error:
Disallow: products
The correct option:
Disallow: /products
or
Disallow: *products
depending on what you want to exclude from indexing.
An incorrect sitemap URL format
The sitemap is for search engine crawlers. They contain recommendations on which pages to crawl first and at what frequency. Having a sitemap helps robots to index the pages they need faster.
The Sitemap URL must contain:
- The full address
- The protocol designation (HTTP: // or HTTPS: //)
- The site name
- The path to the file
- The filename
An example of an error:
Sitemap: /sitemap.xml
Correct option:
Sitemap: https://www.site.ru/sitemap.xml
Incorrect format of the "Crawl-delay" directive
The Crawl-delay directive sets the minimum period between the end of loading one page and the start of loading the next for the robot.
The Crawl-delay directive should be used in cases where the server is heavily loaded and does not have time to process the crawler's requests. The larger the set interval, the lesser the number of downloads during one session.
When specifying an interval, you can use both integer values and fractional values. A period is used as a separator. The measurement unit is in seconds:
Errors include:
- Several directives Crawl-delay;
- Incorrect format of the Crawl-delay directive.
An example of an error:
Crawl-delay: 0,5 second
Correct option:
Crawl-delay: 0.5
Note: Google does not support the Crawl-delay directive. For a Google bot, you can set the frequency of hits in the Search Console webmaster panel. However, the Bing and Yahoo bots do comply with the Crawl-delay directive.
The line contains BOM (Byte Order Mark) - U + FEFF character
BOM (Byte Order Mark - byte sequence marker) is a character of the form U + FEFF, located at the beginning of the text. This Unicode character is used to determine the sequence of bytes when reading information.
When creating and editing a file using standard programs, editors can automatically assign UTF-8 encoding with a BOM tag.
BOM is an invisible character. It doesn't have a graphical expression, so most editors don't show it. But when copied, this symbol can be transferred to a new document.
When using a byte sequence marker in .html files, design settings get confused, blocks are shifted and unreadable character sets may appear, so it is recommended to remove the tag from web scripts and CSS files.
How to get rid of BOM tags?
Getting rid of the PTO is quite tricky. One easy way to do this is to open the file in an editor that can change the document's encoding and resave it with UTF-8 encoding without the BOM.
For example, you can download the Notepad ++ editor for free. Then open the file with the PTO tag in it and select the "Encoding in UTF-8 (without BOM)" item in the "Encodings" menu tab.
How to fix robots.txt Validator errors?
A robots.txt file tells the search engine crawlers which pages it can and can't access. Typical errors and fixes include:
- robots.txt not being in the root directory. To fix this you must simply move your file to the root directory.
- Poor use of wildcard characters, such as * (asterisk) and $ (dollar sign). If misplaced you must locate and move or remove this character.
- Giving access to sites in development. When a site is under construction you can use the disallow instruction to stop it from being crawled, however, once launched these must be removed.
- If you see:
User-Agent: * Disallow: /
This tends to mean that the live page is still being blocked. - Not adding a sitemap URL to your robots.txt. A sitemap URL allows the search engine bots to have a clearer view of your site.